How to identify the physical DIMM from a Machine Check Exception (MCE) memory error log
This is a short rewrite of a post I wrote elsewhere, but which is no longer easily searchable or accessible.
If you’ve got a DIMM that’s going bad and your system supports Machine Check Architecture (MCA) / Machine Check Exceptions (MCEs), you might see alerts about memory errors popping up in your logs or console output. They typically look something like this:
MCA: Bank 9, Status 0x8c000047000800c0
MCA: Global Cap 0x0000000007000c16, Status 0x0000000000000000
MCA: Vendor "GenuineIntel", ID 0x12345, ACPI ID 0
MCA: CPU 0 COR (12345) OVER RD channel ?? memory error
MCA: Address 0x1ba90df400You can use the mcelog command to get a full dump of the MCE:
CPU 0 BANK 9 TSC d52cfb3a01bf02
MISC 1229408000800e8c ADDR 1ba90df400
TIME 1636130520 Fri Nov 5 16:42:00 2021
MemCtrl: Corrected patrol scrub error
STATUS 8c000047000800c0 MCGSTATUS 0
MCGCAP 7000c16 APICID 0 SOCKETID 0
CPUID Vendor Intel Family 6 Model 63The “corrected patrol scrub error” means that the memory controller identified an error during a routine scrub of memory. These can be harmless if they only happen very occasionally, and at different addresses, but if you’re seeing them repeatedly, especially at the same addresses, then it typically means you’ve got a faulty DIMM somewhere.
Using dmidecode -t 20, you can get a list of all memory devices on the system and their respective physical address ranges. Search through the memory device list and look for the one whose address range contains the faulting address. The faulting address is listed in the MCE log above, after “ADDR”, so in my example case it’s 1ba90df400, which corresponds to the following device:
Handle 0x001E, DMI type 20, 35 bytes
Memory Device Mapped Address
Starting Address: 0x01800000000
Ending Address: 0x01BFFFFFFFF
Range Size: 16 GB
Physical Device Handle: 0x001D
[ ... ]This tells you that the memory address with physical device handle 0x001D is the faulty one. Note: remember to look at the “Physical Device Handle” line for the entry, not the “Handle” line at the top of the entry!
To map this to a physical DIMM slot, use dmidecode -t 17. This will give you a list of physical memory devices. Look for the one whose handle matches the physical device handle you just found (i.e. 0x001D in this example case).
Handle 0x001D, DMI type 17, 40 bytes
Memory Device
Array Handle: 0x000F
[ ... ]
Size: 16384 MB
Form Factor: RIMM
Set: None
Locator: DIMM_D1
Bank Locator: NODE 1
Type: DDR4
[ ... ]This tells me that the device is located at “DIMM_D1”, which I can look up in my motherboard manual:
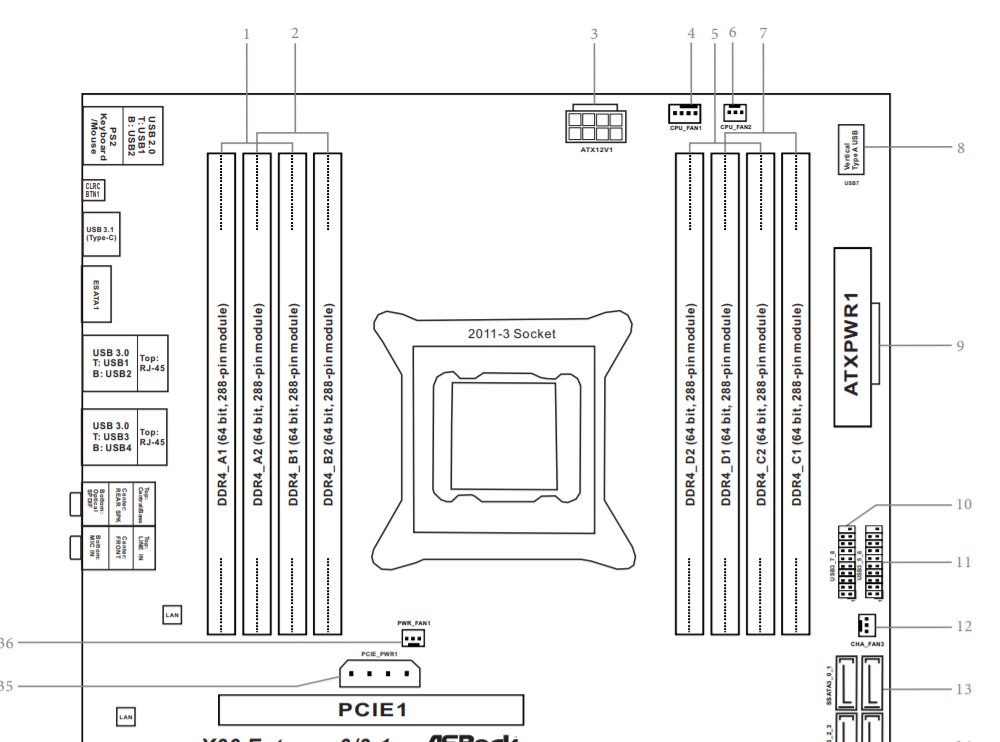
The third slot from the right is marked DDR4_D1, which is the culprit! I can now replace this DIMM with confidence without having to manually pull each one and wait to see if the problem goes away.